




Même si je reste un afficionado de Graphite, j'ai voulu tester les avancées du projet InfluxDB et commencer à l'envisager comme base de données pour la métrologie.
Je vous parlais il y a déjà plus de 6 mois des bases de données chronologiques, ces bases spécialisées dans la gestion des données de type chronologiques, parfaites donc pour accueillir les données de métrologie.
Et bien c’est InfluxDB que j’ai choisi pour succéder petit à petit à Graphite sur mon environnement de supervision. InfluxDB en est déjà à sa version 0.8 au moment d’écrire ces lignes. Le projet avance vite, possède de nombreux contributeurs et toutes les armes aujourd’hui pour envisager de l’utiliser en lieu et place de Graphite.
Décidément, le monde de l’Open Source est impitoyable. À peine avez-vous élu une brique qu’une nouvelle prétend pouvoir prendre la place. Vérifions tout cela dans un setup classique sur Wooster; à savoir Collectd envoie ses données dans InfluxDB donc et Grafana nous visualise toutes ces jolies métriques.
Installation et configuration de InfluxDB
Rien à dire, un .deb à installer sur ma Ubuntu habituelle et basta ! C’est plus simple que l’installation en environnement virtuel de Graphite, pas de doute là-dessus.
Côté configuration, je n’ai rien fait. Je note au passage un plugin qui permet de faire passer InfluxDB pour un serveur Graphite sur le réseau. Il faudra que je teste même si pour l’instant, je vais à l’essentiel.
Une petite vérification via l’interface d’administration fournie que le serveur est bien démarré et prêt. Il suffit de se connecter sur http://localhost:8083 et de fournir root et root pour s’identifier.
Création d’une base de données
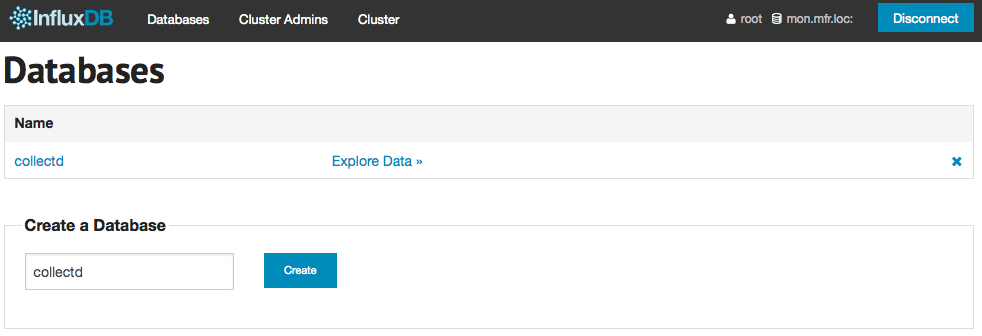
Toujours via cette interface web d’administration, je créé une base de données appelée collectd, allez savoir pourquoi ! J’y affecte un utilisateur collectd avec le mot de passe collectd.
Installation du proxy influxdb-collectd
Il y a plusieurs projets permettant d’envoyer des données de Collectd vers InfluxDB, il faut dire que Collectd est quand même particulièrement complet sur ses possiblités d’envoi de données.
J’ai choisi influxdb-collectd-proxy, qui est récent et programmé en Go comme InfluxDB.
Son installation ne pose pas de souci particulier.
git clone https://github.com/hoonmin/influxdb-collectd-proxy
cd influxdb-collectd-proxy
sudo apt-get install golang-go
makeLe démarrage du démon ainsi compilé se fait par exemple comme suit :
bin/proxy --typesdb="types.db" --database="collectd" --username="collectd" --password="collectd"Le fichier types.db appelé en argument de la commande est le fichier des types de données fourni avec Collectd.
Pour info, voici les options reconnues par le démon au démarrage, obtenu via bin/proxy --help.
Usage of bin/proxy:
-database="": database for influxdb
-influxdb="localhost:8086": host:port for influxdb
-logfile="": path to log file (log to stderr if empty)
-normalize=true: true if you need to normalize data for COUNTER and DERIVE types (over time)
-password="root": password for influxdb
-proxyhost="0.0.0.0": host for proxy
-proxyport="8096": port for proxy
-typesdb="types.db": path to Collectd's types.db
-username="root": username for influxdb
-verbose=false: true if you need to trace the requestsNotre proxy est prêt à recevoir des données depuis Collectd.
Configuration de Collectd
Minimale cette configuration puisque notre proxy se comporte comme un démon « natif » réseau Collectd. C’est donc ce type de bloc qu’il faut activer dans Collectd. Ce bout de configuration fait très bien le boulot.
LoadPlugin network
<Plugin network>
# proxy address
Server "127.0.0.1" "8096"
</Plugin>Reste à redémarrer Collectd et c’est tout.
Vérification de la base de données
Avant d’essayer de grapher nos données Collectd, il est plus prudent de vérifier que les données arrivent bien dans InfluxDB. Il est bien sûr toujours possible d’utiliser la consolde web d’administration pour cela.
Une requête comme celle-ci select * from /.*/ limit 10 permet de voir les dix derniers enregistrements stockés pour chaque métrique remontée par Collectd. Vous avez dit SQL ?
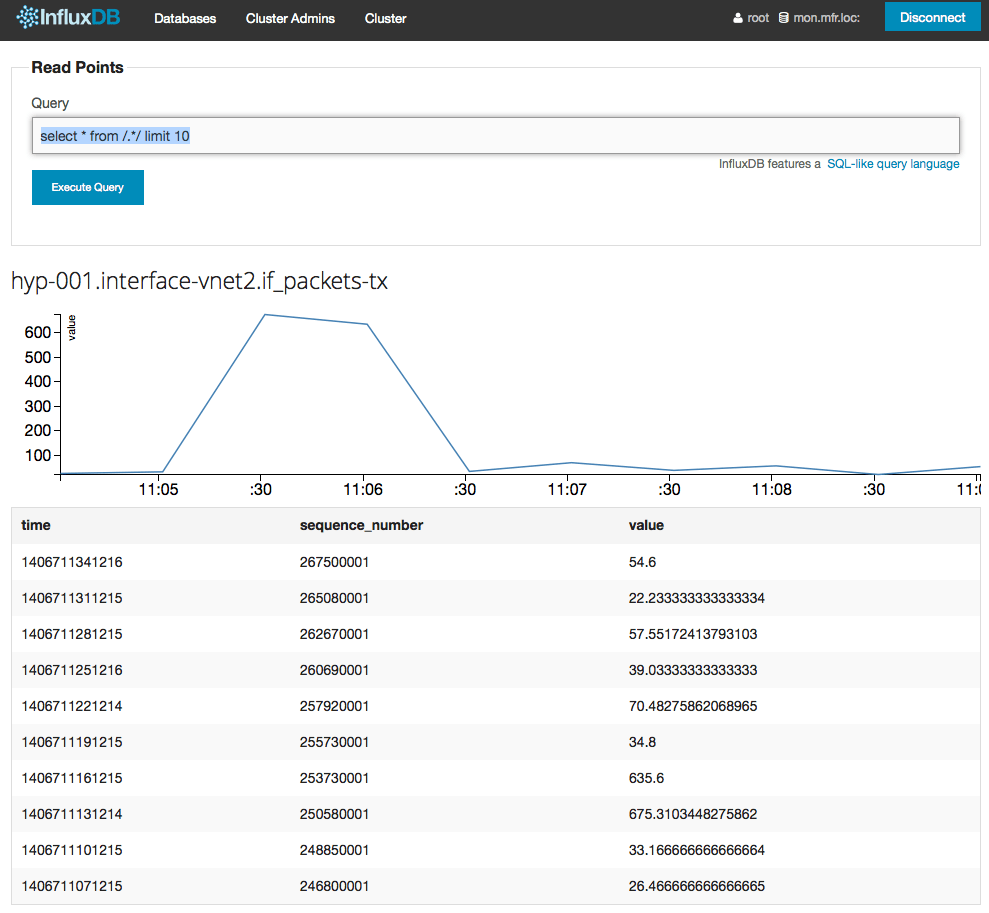
Premier graphe avec Grafana
Puisque tout fonctionne correctement, reste à grapher ces données dans Grafana et ainsi constituer de jolis tableaux de bord.
Configuration de Grafana pour InfluxDB
Le fichier de configuration de Grafana, config.js, gère la notion de datasources.
datasources: {
graphite: {
type: 'graphite',
url: "http://localhost",
default: true
},
influxdb: {
type: 'influxdb',
url: "http://localhost:8086/db/collectd",
username: 'collectd',
password: 'collectd'
},
},Rien d’extraordinaire et c’est tant mieux ! J’ai volontairement laissé le datasource Graphite, souhaitant faire fonctionner les deux systèmes en parallèle pour un certain temps.
Métriques de charge système dans Grafana
Quoi de mieux que cett bonne vieille métrique de load pour un premier test.
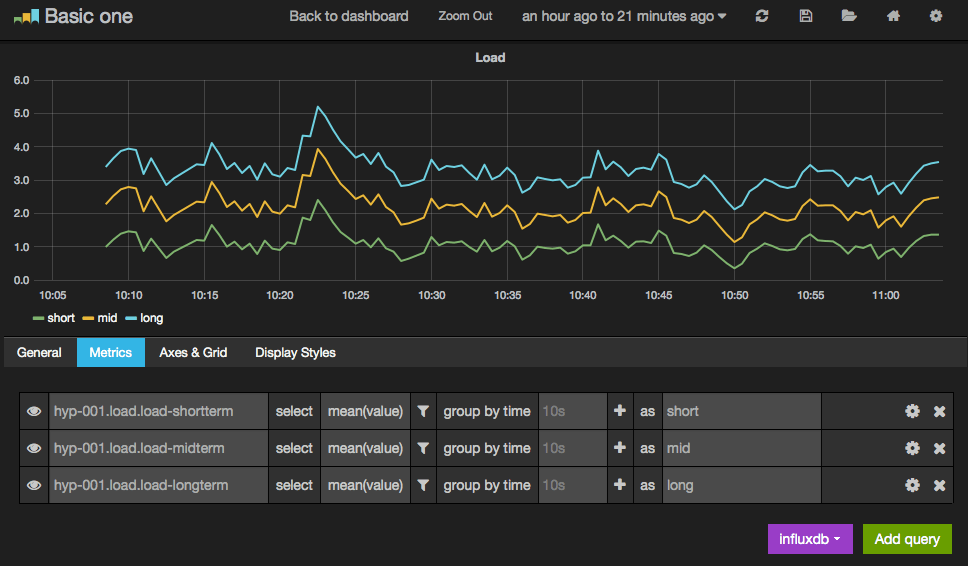
Rien de bien différent par rapport à un graphe Graphite. Il faut juste penser à sélectionner InfluxDB comme source des métriques graphées. J’ai apprécié la possibilité de renommer chaque métrique et d’éviter ainsi les noms à rallonge de type hyp-001.load.load-shortterm.
Encore une belle avancée pour la métrologie
Nous voilà arrivés au terme de cette découverte de InfluxDB en lieu et place de Graphite. Le switch de l’un vers l’autre ne paraît vraiment pas difficile, puisque les sources de données comme Collectd mais aussi StatsD et la partie restitution de données comme Grafana savent déjà utiliser InfluxDB comme backend. La possibilité de laisser les deux en « side-by-side » pendant un certain temps rend la manipulation plutôt sereine. Collectd continue de son côté à ne relever les compteurs qu’une seule fois. Il alimente simplement deux backends !
Au passage, l’administraeur système gagne une base de données clusterisable à volonté et l’assurance de continuer à bénéficier des avancées d’un projet beaucoup plus actif que Graphite. Que du bon !






Vous pourriez également apprécier

Les bases de données de séries chronologiques
Comment un nouveau genre de bases de données est en train de voir le jour pour le stockage des données de la supervision (métriques et événements).

Collectd, Logstash, Kibana: Alternative possible en supervision ?
Comment une boutade lâchée sur Twitter m'oblige à expliquer pourquoi je crois que Collectd, Logstash, Elasticsearch et Kibana peuvent former les bases d'une solution complète de supervison en 2014.

Graphite & StatsD: Le tandem de choix pour vos métriques
Présentation du couple « infernal » de la métrologie; à savoir Graphite et StatsD.