




Comment une boutade lâchée sur Twitter m'oblige à expliquer pourquoi je crois que Collectd, Logstash, Elasticsearch et Kibana peuvent former les bases d'une solution complète de supervison en 2014.
Tout a commencé comme une blague avec un tweet que j’ai lâché mardi soir et qui disait ceci:
S’en est suivi une conversation non dénuée d’un soupçon de troll visant à définir ce qu’est une solution complète de supervision.
Du coup, je me suis piqué au jeu et ai décidé d’étayer un peu mon propos pour expliquer pourquoi je pense que Collectd, Logstash, Elasticsearch et Kibana peuvent former le quatuor de base d’une solution complète de supervision. Notez que je parle désormais de base de solution complète de supervision. C’était ce que j’avais en tête en fait mais ça dépassait les 140 caractères de Twitter et comme disait Christian Clavier dans le Père Noël est une ordure:
« Ça dépend »… Oui, ça évidemment, on vous demande de répondre par OUI ou par NON, alors forcement : « ça dépend », ça dépasse !
Revenons à ce qui nous intéresse: Pourquoi notre quatuor peut former la base d’une solution complète de supervision un tant soit peu modulaire ? Je viens d’ajouter au passage une caractéristique à la définition de ce que peut être une solution complète…
Le quatuor
Notre base de solution est donc composée de quatre briques principales qui sont:
Collectd

Collectd est un démon qui collecte à intervalles réguliers des statistiques sur les performances d’un système et qui offre les mécanismes pour stocker les valeurs récupérées de plusieurs façons, comme par exemple des fichiers RRD.
Collectd est un agent de collecte très complet. Il suffit pour s’en rendre compte de consulter la liste des plugins1 « nativement » disponibles. Et si vous ne trouvez pas votre bonheur dans cette liste, vous savez ce qu’il vous reste à #!/bin/bash. Il fonctionne sur plateforme Linux.
Vous pouvez installer Collectd par le gestionnaire de paquets de votre distribution ou via les sources en suivant ce tutoriel sur monitoring-fr.org.
Logstash

Logsatsh est un outil pour gérer des événements et des fichiers journaux. Vous pouvez l’utiliser pour collecter des fichiers journaux, les analyser et les stocker pour une utilisation ultérieure (la recherche par exemple).
À l’instar de Collectd, la liste des inputs/outputs2 de Logstash est impressionnante et permet d’envisager de belles possibilités.
Au fil du temps, Logstash est devenu beaucoup plus complet. Son champ d’utilisation peut s’étendre désormais aux traitement des métriques, même si les logs restent son cheval de bataille principal.
Elasticsearch

Elasticsearch est un moteur d’indexation plein texte construit sur Apache Lucene. Il est sans schéma, scalable, hautement disponible et possède une interface REST complète.
C’est le point le plus particulier de cette solution puisque Elastisearch est utilisé par Logsatsh comme stockage, base de données et pas seulement comme moteur d’indexation.
Kibana

Kibana est une interface de visualisation des données collectées et stockées par nos trois précédents outils. Une démonstration est disponible.
À noter que les trois derniers possèdent désormais un espace commun sur la site de Elasticsearch. Qui a parlé de convergence ?
Maintenant que les acteurs sont présentés, voyons ce qu’il est possible de faire avec.
Le périmètre de supervision
Comme nous sommes sur Wooster, étudions les besoins d’une architecture distribuée plutôt classique (mais pas trop) servant à délivrer un site web de type Wordpress par exemple. Vous pouvez remplacer Wordpress par un paquet d’autres CMS !
- Une ou plusieurs instances Nginx en frontal connectées à…
- Une ou plusieurs instances PHP5-FPM connectées à…
- Une ou plusieurs instances MySQL.
Il y normalement quelques switchs, routeurs, firewalls pour connecter le tout à la toile mais bon je pense que vous avez une idée du genre de périmètre.
L’architecture de supervision
C’est une architecture classique client-serveur avec comme particularité de favoriser le mode push (passif) plutôt que le mode pull (actif) comme le fait Nagios.
Architecture serveur de supervision
Ceci donne ce type d’architecture. Redis est utilisé comme cache mémoire avant traitement des données brutes par Logstash. Tout le reste est envoyé en direct à Logstash. De nombreuses variantes peuvent être possibles3.
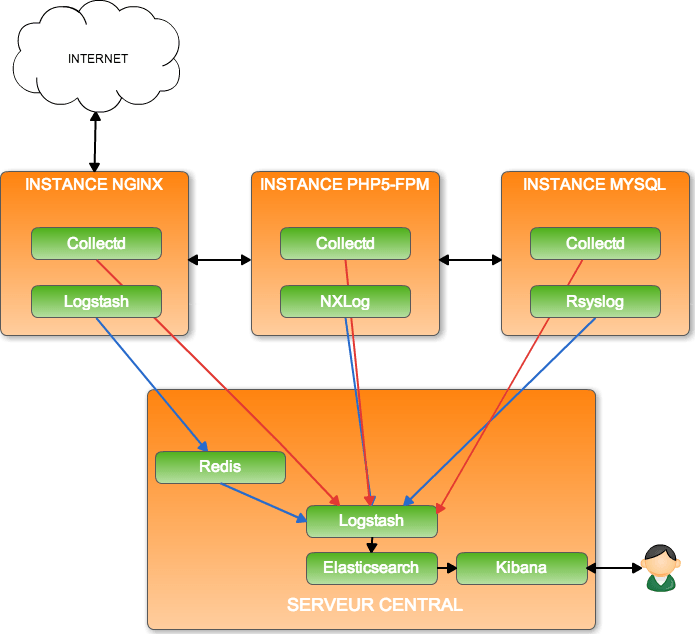
Vous pouvez ajouter autant d’instances que nécessaires côté serveur pour traiter vos flux de données puisque Logstash et Elasticsearch peuvent être multipliés (cluster) au besoin.
Architecture client de supervision
Nous utilisons un client distinct pour événements et métriques.
Métriques
Collectd est installé sur chaque instance, un peu comme vous le feriez avec NRPE pour pouvoir récupérer les métriques locales de l’instance soit par exemple:
- Processeur
- Mémoire
- Processus
- Espace disque
Collectd envoie ces données vers un démon Collectd centralisateur, ou un démon Logstash se faisant passer pour tel. Nous verrons le cas un peu plus loin dans cet article.
Sur plateforme Windows, il est possible d’utiliser le plugin WMI de Logsatsh pour collecter celles-ci puisque Collectd ne fonctionne lui que sur Linux. Un client Collectd payant est néanmoins disponible sur Windows.
Vous pouvez récupérer n’importe quelle compteur SNMP depuis Collectd.
Événements
Chaque instance est configurée pour faire suivre les fichiers de logs (ou lignes de fichiers) intéressants vers une instance Logstash soit:
- Logs Nginx
- Logs MySQL
- Logs PHP5-FPM
- Logs système
Côté logiciel, vous pouvez utiliser Syslog-ng, Rsyslog, NXlog voir Logstash (peut être un peu overkill) pour cette tâche.
Logstash possède un plugin pour gérer les interruptions SNMP.
Toute la puissance de Logstash se trouve dans sa capacité à formater correctement des données très diverses. J’ai personnellement eu de très bons résultats en utilisant Logstash comme instance centralisatrice de logs venant de systèmes Linux et Windows. Logstash m’a permis de normaliser ces messages, de façon propre, quelques soit leur provenance. La recherche devient alors possible sur n’importe quel type de messages.
La collecte des données de supervision
Cette solution est capable de vous collecter à peu près toutes les métriques et événements disponibles sur vos systèmes et ce en quasi temps réel.
Vous pouvez également soumettre des métriques depuis les valeurs enregistrées dans les fichiers de logs. Vous pouvez de cette façon comptabiliser toute erreur 404 ou le nombre de hits sur vos serveur Nginx.
Collecte en mode push
C’est le mode de fonctionnement « par défaut » de cette solution puisque les événements (logs) et les métriques (collectd) sont poussées à intervalles réguliers ou au moment où ils surviennent vers le serveur central de supervision. Ce mode de fonctionnement est parfait pour recevoir des données en « temps réel ».
Il est par contre inadapté, à mon humble avis, quand il s’agit de vérifier la connexion des différents éléments de notre architecture web entre eux. Le mieux par exemple pour tester la disponibilité de la base MySQL est de tester celle-ci depuis le composant qui en a besoin; soit PHP5-FPM dans notre cas. Les aficionados Nagios retrouvent d’un coup le sourire, il faut faire du polling !
Collecte en mode pull
Et ça tombe bien puisque Collectd peut tout à fait jouer ce rôle, que ce soit de façon individuelle comme l’exemple MySQL ci-dessus ou de façon globale comme vous créez un poller pour Nagios. Ici, c’est un poller Collectd qui enverra les données récupérées à Logstash via le tout nouveau plugin dédié à cette tâche. Logstash fonctionne alors comme une instance centralisatrice Collectd4.
La visualisation
Assurée par Kibana, celle-ci se base sur le principe de tableaux de bord (dashboards) qu’il faut composer avec des widgets. L’interface permet de visualiser, grapher, analyser toutes les données disponibles dans Elasticsearch.
Varitions sur un même thème
Les variations que vous pouvez apporter à cette base sont nombreuses. Vu les nombreux plugins, que ce soit en entrée ou en sortie, tout paraît possible !
Vous pouvez par exemple ajouter Riemann au mix. Les connecteurs existent entre celui-ci et Logstash. Une variante peut être de stocker les métriques dans une base de données de type séries chronologiques pour ne conserver que les événements dans Elasticsearch.
Cette variante rassurera ceux qui souhaitent garder un fonctionnement à la RRD (taille fixe des bases à la création au prix d’une perte de précision sur les données les plus anciennes).
Au delà de la supervision technique
Étudiez5 ce cas d’utilisation pour voir comment analyser, monitorer votre e-reputation sur Twitter et obtenir ce résultat final plus que probant.
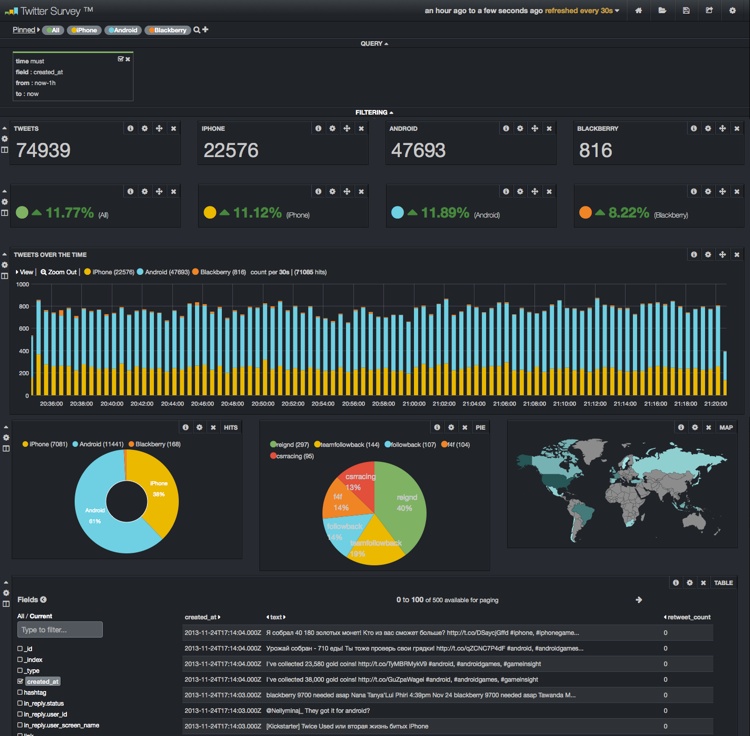
Au passage, cet exemple utilise une des fonctionnalités les plus puissantes d’Elasticsearch, à savoir les “rivers”. Il en existe aujourd’hui pour CouchDB, RabbitMQ, Twitter et Wikipedia et il y a fort à parier que d’autres seront rapidement disponibles.
Ne jetez pas votre Nagios/Icinga/Shinken/Centreon/Zabbix/… !
C’est une solution innovante qui met à mal nombre des principes édictés depuis longtemps dans le monde de la supervision Open Source. Un temps d’adaptation est donc nécessaire pour capter la logique et les nombreuses possibilités offertes ainsi que les manquements.
La notion d’état d’un hôte ou service au sens Nagios du terme n’est pas présente par exemple. Et vous pourrez également toujours utiliser votre Nagios pour la gestion des notifications, absentes de cette base. Il y a d’ailleurs un plugin Logstash qui permet de remonter des événements vers Nagios à des fins de notifications ou autres d’ailleurs.
La configuration de l’ensemble pour arriver au résultat final peut également être assez conséquente et faite de nombreux essais/erreurs en fonction de la complexité des données à traiter.
La solution proposée n’est pas iso-fonctionnelle avec une solution traditionnelle; Pas de cartographie aussi souple que Nagvis par exemple. Et même si Kibana est une excellente interface, il y a encore de quoi faire pour multiplier les formes de visualisation.
Par contre, en matière de collecte et de stockage, c’est clairement l’une des plus puissantes proposées aujourd’hui. Le traitement des fichiers de logs est sans commune mesure avec ce qu’il est possible de faire dans une solution basée sur Nagios. Les métriques systèmes et autres peuvent être collectées toutes les 10 secondes, voir moins; chose impensable dans le monde Nagios.
Conclusion…
Il me fallait bien plus de 140 caractères pour expliquer ce que j’avais en tête et je crois vraiment avoir montré (peut-être même démontré) que ces briques peuvent être la base d’une solution complète de supervision.
Cela sous-entend bien qu’il faudra mixer, mélanger ces ingrédients de base avec d’autres pour arriver à une solution complète de supervision; que Jean Gabès, auteur de Shinken, a fini par définir dans notre discussion Twitter:
ok donc je reformule: « 1 seule solution pour tout faire » :)
La bonne formulation du Tweet de départ aurait donc peut-être dû être: Est-ce que Collectd, Logstash, Elasticsearch et Kibana peuvent former les bases d’une solution complète de supervision en 2014 ?
Vous aurez tout le temps de réfléchir à tout ça entre la dinde et la bûche dans peu de temps. C’est toujours un bon moment pour un peu de métaphysique. Quoiqu’il en soit, pour ma part, j’espère vous avoir donné envie de tester un peu ce genre de solutions (vous avez de quoi faire) et j’éradiquerais tout troll qui pourrait se pointer pour pourrir la bûche !
Logstash, Graylog2 et Simple Event Correlator sur monitoring-fr.org.↩
Tutoriel en anglais sur Collectd + Logstash.↩






Vous pourriez également apprécier

Les bases de données de séries chronologiques
Comment un nouveau genre de bases de données est en train de voir le jour pour le stockage des données de la supervision (métriques et événements).

Graphite & StatsD: Le tandem de choix pour vos métriques
Présentation du couple « infernal » de la métrologie; à savoir Graphite et StatsD.

Grafana: L'interface web de Graphite
Grafana est l'une des meilleures interfaces disponibles pour Graphite et un excellent complément à Kibana.